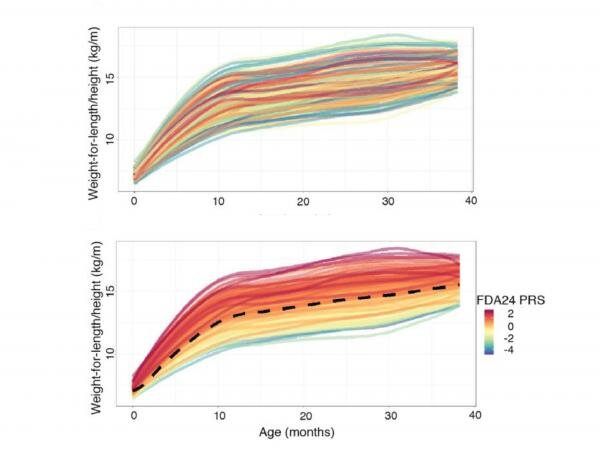
 indicating a greater risk of a child developing obesity. Credit: Sarah Craig et al., Econometrics and Statistics.")
Newly developed risk scores synthesize genetic information into an easy-to-interpret metric that could help clinicians identify young children most at risk of developing obesity.
The study, led by researchers at Penn State, used novel statistical methods to establish scoring criteria using data collected from young children. The research also demonstrates that robust results are attainable from studies that are orders-of-magnitude smaller than typical genetic studies when comprehensive data is collected over time and used in conjunction with powerful statistical tools.
“About 18% of children in the United States are obese, and 6% are severely obese,” said Sarah Craig, assistant research professor of biology at Penn State. “If we can identify children most at risk, we might be able to prevent obesity from developing in the first place. In this study, we produced risk scores based on genetic information that clinicians could potentially use to identify young children who would most benefit from intervention strategies.”
This study is part of a larger project called INSIGHT (Intervention Nurses Start Infants Growing on Healthy Trajectories), coordinated through the Penn State Health Milton S. Hershey Medical Center, in which researchers and clinicians work together to identify biological and social risk factors for obesity and the impacts of responsive parenting interventions during a child’s early life. The research team collected longitudinal data—periodically 8 times between birth and three years of age—including weight, height, and behavioral and environmental variables—on nearly 300 children. They also collected a blood sample for genetic analyses from each of the children, which served as the basis for developing risk scores. The team published their results in a paper appearing in the journal Econometrics and Statistics.
The risk scores—called “polygenic risk scores” because they are based on many genetic locations across the genome—distill vast genetic information into an easy-to-grasp number. Typically, the scores incorporate information from a number of single nucleotide polymorphisms (SNPs), or locations in the genome where single letters of the DNA alphabet can vary among people, that are most related to the metrics of interest—in this case, growth rates and obesity.
“Previous attempts to produce polygenic risk scores for obesity were developed using genetic information from adults or older children and include anywhere from a hundred to two million SNPs,” said Kateryna Makova, professor of biology and Verne M. Willaman Chair of Life Sciences at Penn State. “Such high numbers are challenging and potentially expensive to consistently reproduce, especially in a clinical setting. We produced two score options with far fewer SNPs—one with 24 and one with 5—that nonetheless can provide valuable information to researchers and clinicians.”
The research team used novel statistical techniques from a field called functional data analysis to identify the SNPs most related to obesity, which were then incorporated into the scores.
“Unlike many genetic studies, which collect data on a single measurement, like for instance body mass index—BMI, and at a single point of time, we took advantage of the longitudinal data collected over time,” said Francesca Chiaromonte, professor of statistics and Huck Chair in Statistics for the Life Sciences at Penn State. “Several measurements of weight and height over time yield a growth curve for each child, and we can analyze the shapes of the curves for the children in our cohort using functional data analysis. We took advantage of this richer data at every step of the analysis.”
Genetic data yields millions of SNPs that must be analyzed, and the team used several techniques to narrow down the pool to the SNPs most related to the growth curves and measures of obesity.
“We first evaluated the impact of each SNP individually on obesity-related measures, as a way to remove those that were clearly not related,” said Ana Kenney, graduate student in statistics at Penn State at the time of the research and now a postdoctoral researcher at the University of California, Berkeley. “Some studies choose to stop at this step, however we narrowed down the pool even more by looking at all the remaining SNPs simultaneously and eliminating those that did not appear to have an impact when considered along with others.”
This process yielded 24 SNPs that the researchers incorporated into a polygenic risk score. The scores, built based on growth curves, turned out also to be related to other, more commonly used measures; they were higher in children with higher conditional weight gain—the change in weight gain over the first 6 months—and with rapid infant weight gain—a predictor of obesity later in life.
The research team further narrowed the pool to five of the most “stable” SNPs—the SNPs that had the most impact even when they perturbed the data. From these five SNPS, they produced a second score that could be used as a simpler alternative.
“Although the score with 24 SNPs is more powerful than the score with 5 SNPs, we verified that both are useful measures of obesity risk, and we believe either could be used in a clinical setting,” said Matthew Reimherr, associate professor of statistics at Penn State. “A score that requires fewer SNPs to be typed should make it easier to produce in clinics.”
Notably, the scores produced in this study also predicted obesity in older children and in adults, which the research team verified using publicly available datasets. However, scores produced from other studies that were based on obesity information in adults did not translate to the young children in this study.
“This suggests that the genetic signals related to obesity that we see in early childhood are critical across the lifecourse,” said Ian Paul, professor of pediatrics and public health sciences at Penn State College of Medicine. “However, as people age, they start manifesting other parts of their genetic composition. Scores based on early signals seem to be more robust throughout a person’s lifetime. This highlights the need for more studies that focus on identifying risk and preventing obesity in young children, particularly in the ‘first 1000 days’ spanning pregnancy and the first two years after birth.”
The study also demonstrates that smaller studies that deeply characterize individuals and take advantage of functional data analysis techniques can be a powerful alternative to typical large-scale genetic studies.
“These techniques can open doors to smaller labs with fewer resources,” said Craig. “By working carefully and rigorously to collect longitudinal data from more targeted cohorts, and by using powerful statistical techniques, you can still manage to find useful information with a study that is orders-of-magnitude smaller than typical GWAS studies.”
In addition to Craig, Makova, Chiaromonte, Kenney, Reimherr and Paul, the research team includes Junli Lin, a research associate at Penn State at the time of the research; Leann Birch, late professor of foods and nutrition at the University of Georgia who helped lead INSIGHT; Jennifer Savage, director for the Center of Childhood Obesity Research and associate professor of nutritional sciences at Penn State; and Michele Marini, research technologist and statistician for the Center of Childhood Obesity Research at Penn State.
Source: Read Full Article